Where Is Data Stored
For each column family, there are 3 layer of data stores: memtable, commit log and SSTable.
1For efficiency, Cassandra does not repeat the names of the columns in memory or in the SSTable. For example, data is inserted using these CQL statements:
INSERT INTO k1.t1 (c1) VALUES (v1);
INSERT INTO k2.t1 (c1, c2) VALUES (v1, v2);
INSERT INTO k1.t1 (c1, c3, c2) VALUES (v4, v3, v2);
In the memtable, Cassandra stores this data:
k1 c1:v4 c2:v2 c3:v3
k2 c1:v1 c2:v2
In the commit log on disk, Cassandra stores this data:
k1, c1:v1
k2, c1:v1 C2:v2
k1, c1:v4 c3:v3 c2:v2
In the SSTable on disk, Cassandra stores this data after flushing the memtable:
k1 c1:v4 c2:v2 c3:v3
k2 c1:v1 c2:v2
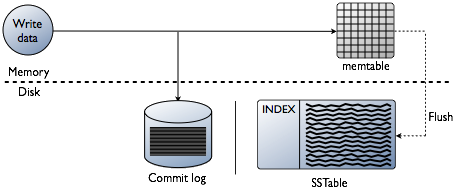
The Write Path
When a write occurs, Cassandra stores the data in a structure in memory, the memtable, and also appends writes to the commit log on disk.
The memtable is a write-back cache of data partitions that Cassandra looks up by key. The more a table is used, the larger its memtable needs to be. Cassandra can dynamically allocate the right amount of memory for the memtable or you can manage the amount of memory being utilized yourself. The memtable, unlike a write-through cache, stores writes until reaching a limit, and then is flushed.
When memtable contents exceed a configurable threshold, the memtable data, which includes indexes, is put in a queue to be flushed to disk. To flush the data, Cassandra sorts memtables by partition key and then writes the data to disk sequentially. The process is extremely fast because it involves only a commitlog append and the sequential write.
Data in the commit log is purged after its corresponding data in the memtable is flushed to the SSTable. The commit log is for recovering the data in memtable in the event of a hardware failure.
SSTables are immutable, not written to again after the memtable is flushed. Consequently, a partition is typically stored across multiple SSTable files So, if a row is not in memtable, a read of the row needs look-up in all the SSTable files. This is why read in Cassandra is much slower than write.
Compaction
To improve read performance as well as to utilize disk space, Cassandra periodically does compaction to create & use new consolidated SSTable files instead of multiple old SSTables.
2You can configure two types of compaction to run periodically: SizeTieredCompactionStrategy and LeveledCompactionStrategy.
- SizeTieredCompactionStrategy is designed for write-intensive workloads
- LeveledCompactionStrategy for read-intensive workloads
For more information about compaction strategies, see When to Use Leveled Compaction and Leveled Compaction in Apache Cassandra.